No product gets built without at least one good supply chain war story – especially true in these strange times. Before we get into the details of the story, I feel it’s worth understanding a bit more about the part that caused me so much trouble: what it does, and why it’s so special.
The Part that Could Not Be Found
There’s a bit of magic in virtually every piece of modern electronics involved in the generation of internal timing signals. It’s called an oscillator, and typically it’s implemented with a precisely cut fleck of quartz crystal that “rings” when stimulated, vibrating millions of times per second. The accuracy of the crystal is measured in parts-per-million, such that over a month – about 2.5 million seconds – a run-of-the-mill crystal with 50ppm accuracy might drift by about two minutes. In mechanical terms it’s like producing 1kg (2.2 pound) bags of rice that have precisely no more and no less than one grain of rice compared to each other; or in CS terms it’s about 15 bits of precision (it’s funny how one metric sounds hard, while the other sounds trivial).
One of the many problems with quartz crystals is that they are big. Here’s a photo from wikipedia of the inside of a typical oscillator:

CC BY-SA 4.0 by Binarysequence via Wikipedia
The disk on the left is the crystal itself. Because the frequency of the crystal is directly related to its size, there’s a “physics limit” on how small these things can be. Their large size also imposes a limit on how much power it takes to drive them (it’s a lot). As a result, they tend to be large, and power-hungry – it’s not uncommon for a crystal oscillator to be specified to consume a couple milliamperes of current in normal operation (and yes, there are also chips with built-in oscillator circuits that can drive crystals, which reduces power; but they, too, have to burn the energy to charge and discharge some picofarads of capacitance millions of times per second due to the macroscopic nature of the crystal itself).
A company called SiTime has been quietly disrupting the crystal industry by building MEMS-based silicon resonators that can outperform quartz crystals in almost every way. The part I’m using is the SiT8021, and it’s tiny (1.5×0.8mm), surface-mountable (CSBGA), consumes about 100x less power than the quartz-based competition, and has a comparable frequency stability of 100ppm. Remarkably, despite being better in almost every way, it’s also cheaper – if you can get your hands on it. More on that later.
Whenever something like this comes along, I always like to ask “how come this didn’t happen sooner?”. You usually learn something interesting in exploring that question. In the case of pure-silicon oscillators, they have been around forever, but they are extremely sensitive to temperature and aging. Anyone who has designed analog circuits in silicon are familiar with the problem that basically every circuit element is a “temperature-to-X” converter, where X is the parameter you wish you could control. For example, a run of the mill “ring oscillator” with no special compensation would have an initial frequency accuracy of about 50% – going back to our analogies, it’d be like getting a bag of rice that nominally holds 1kg, but is filled to an actual weight of somewhere between 0.5kg and 1.5kg – and you would get swings of an additional 30% depending upon the ambient temperature. A silicon MEMS oscillator is a bit better than that, but its frequency output would still vary wildly with temperature; orders of magnitude more than the parts-per-million specified for a quartz crystal.
So, how do they turn something so innately terrible into something better-than-quartz? First I took a look at the devices under a microscope, and it’s immediately obvious that it’s actually two chips that have been bonded face-to-face with each other.

Edge-on view of an SiT8021 already mounted on a circuit board.
I deduced that a MEMS oscillator chip is nestled between the balls that bond the chip to the PCB. I did a quick trawl through the patents filed by SiTimes, and I’m guessing the MEMS oscillator chip contains at least two separate oscillators. These oscillators are intentionally different, so that their frequency drift with temperature also have different, but predictable, curves. They can use the relative difference of the frequencies to very precisely measure the absolute temperature of the pair of oscillators by comparing the instantaneous difference between the two frequencies. In other words, they took the exact problem that plagues silicon designs, and turned it into a feature: they built a very precise temperature sensor out of two silicon oscillators.
With the temperature of the oscillators known to exquisite precision, one can now compensate for the temperature effects. That’s what the larger of the two chips (the one directly attached to the solder balls) presumably does. It computes an inverse mapping of temperature vs. frequency, constantly adjusting a PLL driven by one of the two MEMs oscillators, to derive a precise, temperature-stable net frequency. The controller chip presumably also contains a set of eFuses that are burned in the factory (or by the distributor) to calibrate and set the initial frequency of the device. I didn’t do an acid decap of the controller chip, but it’s probably not unreasonable for it to be fabricated in 28nm silicon; at this geometry you could fit an entire RISC-V CPU in there with substantial microcode and effectively “wrap a computer” around the temperature drift problem that plagues silicon designs.
Significantly, the small size of the MEMS resonator compared to a quartz crystal, along with its extremely intimate bonding to the control electronics, means a fundamentally lower limit on the amount of energy required to sustain resonance, which probably goes a long way towards explaining why this circuit is able to reduce active power by so much.
The tiny size of the controller chip means that a typical 300mm wafer will yield about 50,000 chips; going by the “rule of thumb” that a processed wafer is roughly $3k, that puts the price of a raw, untested controller chip at about $0.06. The MEMs device is presumably a bit more expensive, and the bonding process itself can’t be cheap, but at a “street price” of about $0.64 each in 10k quantities, I imagine SiTime is still making good margin. All that being said, a million of these oscillators would fit on about 18 wafers, and the standard “bulk” wafer cassette in a fab holds 25 wafers (and a single fab will pump out about 25,000 – 50,000 wafers a month); so, this is a device that’s clearly ready for mobile-phone scale production.
Despite the production capacity, the unique characteristics of the SiT8021 make it a strong candidate to be designed into mobile phones of all types, so I would likely be competing with companies like Apple and Samsung for my tiny slice of the supply chain.
The Supply Chain War Story
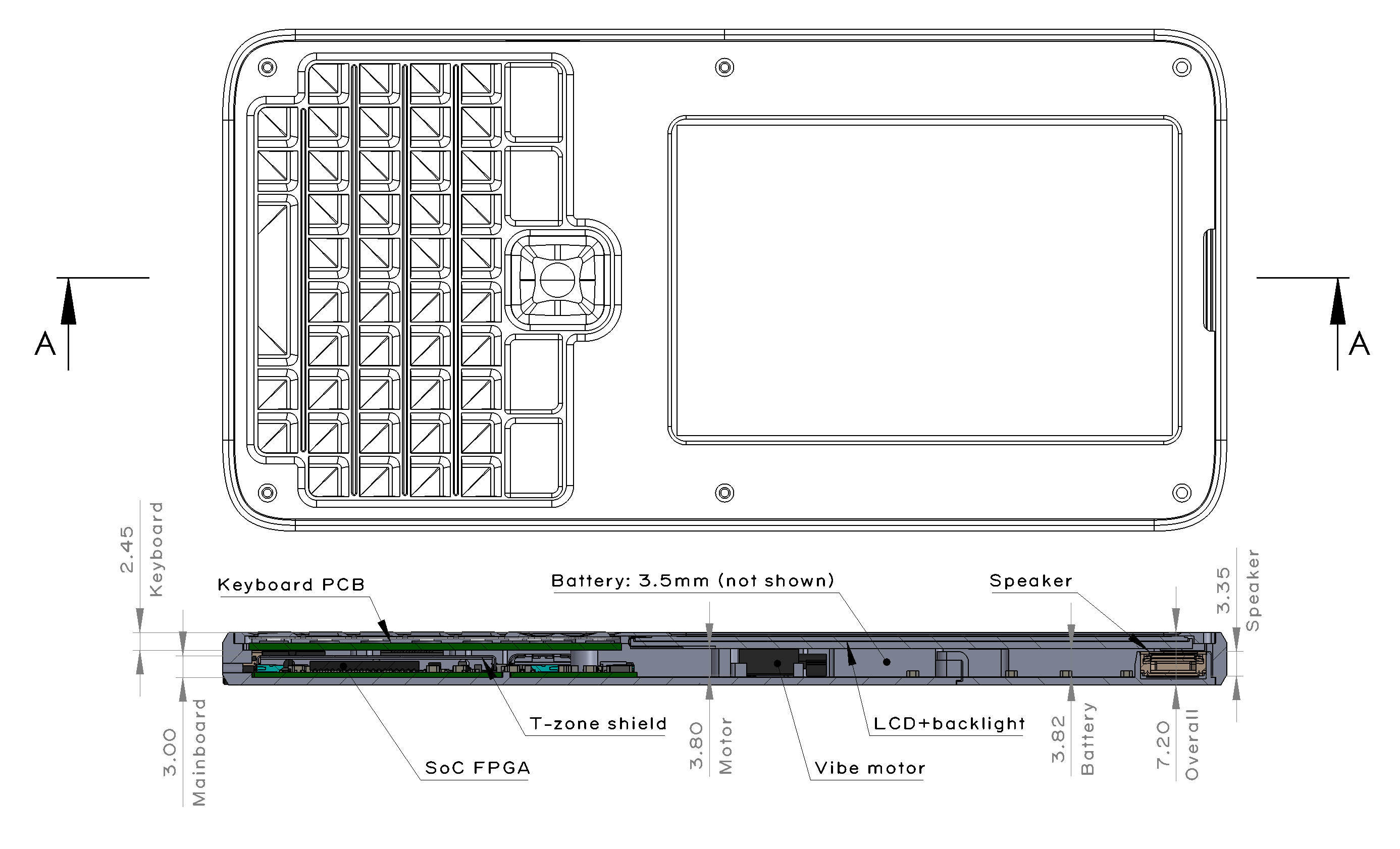
It’s clearly a great part for a low-power mobile device like Precursor, which is why I designed it into the device. Unfortunately, there’s also no real substitute for it. Nobody else makes a MEMS oscillator of comparable quality, and as outlined above, this device is smaller and orders of magnitude lower power than an equivalent quartz crystal. It’s so power-efficient that in many chips it is less power to use this off-chip oscillator, than to use the built-in crystal oscillator to drive a passive crystal. For example, the STM32H7 HSE burns 450uA, whereas the SiT8021 runs at 160uA. To be fair, one also has to drive the pad input capacitance of the STM32, but even with that considered you’re probably around 250uA.
To put it in customer-facing terms, if I were forced to substitute commonly available quartz oscillators for this part, the instant-on standby time of a Precursor device would be cut from a bit over 50 hours down to about 40 hours (standby current would go from 11mA up to 13mA).
If this doesn’t make the part special enough, the fact that it’s an oscillator puts it in a special class with respect to electromagnetic compliance (EMC) regulations. These are the regulations that make sure that radios don’t interfere with each other, and like them or not, countries take them very seriously as trade barriers – by requiring expensive certifications, you’re able to eliminate the competition of small upstarts and cheap import equipment on “radio safety” grounds. Because the quality of radio signals depend directly upon the quality of the oscillator used to derive them, the regulations (quite reasonably) disallow substitutions of oscillators without re-certification. Thus, even if I wanted to take the hit on standby time and substitute the part, I’d have to go through the entire certification process again, at a cost of several thousand dollars and some weeks of additional delay.
Thus this part, along with the FPGA, is probably one of the two parts on the entire BOM that I really could not do without. Of course, I focused a lot on securing the FPGA, because of its high cost and known difficulty to source; but for want of a $0.68 crystal, a $565 product would not be shipped…
The supply chain saga starts when I ordered a couple thousand of these in January 2021, back when it had about a 30 week lead time, giving a delivery sometime in late August 2021. After waiting about 28 weeks, on August 12th, we got an email from our distributor informing us that they had to cancel our entire order for SiT8021s. That’s 28 weeks lost!
The nominal reason given was that the machine used to set the frequency of the chips was broken or otherwise unavailable, and due to supply chain problems it couldn’t be fixed anytime soon. Thus, we had to go to the factory to get the parts. But, in order to order direct from the factory, we had to order 18,000 pieces minimum – over 9x of what I needed. Recall that one wafer yields 58,000 chips, so this isn’t even half a wafer’s worth of oscillators. That being said, 18,000 chips would be about $12,000. This isn’t chump change for a project operating on a fixed budget. It’s expensive enough that I considered recertification of the product to use a different oscillator, if it weren’t for the degradation in standby time.
Panic ensues. We immediately trawl all the white-market distributor channels and buy out all the stock, regardless of the price. Instead of paying our quoted rate of $0.68, we’re paying as much as $1.05 each, but we’re still short about 300 oscillators.
I instruct the buyers to search the gray market channels, and they come back with offers at $5 or $6 for the $0.68 part, with no guarantee of fitness or function. In other words, I could pay 10x of the value of the part and get a box of bricks, and the broker could just disappear into the night with my money.
No deal. I had to do better.
By this time, every distributor was repeating the “18k Minimum Order Quantity (MOQ) with long lead time” offer, and my buyers in China waved the white flag and asked me to intervene. After trawling the Internet for a couple hours, I discover that Element14 right here in Singapore (where I live) claims to be able to deliver small quantities of the oscillator before the end of the year. It seems too good to be true.
I ask my buyers in China to place an order, and they balk; the China office repeats that there is simply no stock. This has happened before, due to trade restrictions and regional differences the inventory in one region may not be orderable in another, so I agree to order the balance of the oscillators with a personal credit card, and consign them directly to the factory. At this point, Element14 is claiming a delivery of 10-12 weeks on the Singapore website: that would just meet the deadline for the start of SMT production at the end of November.
I try to convince myself that I had found the solution to the problem, but something smelled rotten. A month later, I check back into the Element14 website to see the status of the order. The delivery had shifted back almost day-for-day to December. I start to suspect maybe they don’t even carry this part, and it’s just an automated listing to honeypot orders into their system. So, I get on the phone with an Element14 representative, and crazy enough, she can’t even find my order in her system even though I can see the order in my own Element14 account. She tells me this is not uncommon, and if she can’t see it in her system, then the web order will never be filled. I’m like, is there any way you can cancel the order then? She’s like “no, because I can’t see the order, I can’t cancel it.” But also because the representative can’t see the order, it also doesn’t exist, and it will never be filled. She recommends I place the order again.
I’m like…what the living fuck. Now I’m starting to sweat bullets; we’re within a few weeks of production start, and I’m considering ordering 18,000 oscillators and reselling the excess as singles via Crowd Supply in a Hail Mary to recover the costs. The frustrating part is, the cost of 300 parts is small – under $200 – but the lack of these parts blocks the shipment of roughly $170,000 worth of orders. So, I place a couple bets across the board. I go to Newark (Element14, but for the USA) and place an order for 500 units (they also claimed to be able to deliver), and I re-placed the order with Element14 Singapore, but this time I put a Raspberry Pi into the cart with the oscillators, as a “trial balloon” to test if the order was actually in their system. They were able to ship the part of the order with the Raspberry Pi to me almost immediately, so I knew they couldn’t claim to “lose the order” like before – but the SiT8021 parts went from having a definitive delivery date to a “contact us for more information” note – not very useful.
I also noticed that by this time (this is mid-October), Digikey is listing most of the SiT8021 parts for immediately delivery, with the exception of the 12MHz, 1.8V version that I need. Now I’m really starting to sweat – one of the hypothesis pushed back at my by the buyer in China was that there was no demand for this part, so it’s been canceled and that’s why I can’t find it anywhere. If the part’s been canceled, I’m really screwed.
I decide it’s time to reach out to SiTime directly. Through hook and crook, I get in touch with a sales rep, who confirms with me that the 12MHz, 1.8V version is a valid and orderable part number, and I should be able to go to Digikey to purchase it. I inform the sales rep that the Digikey website doesn’t list this part number, to which they reply “that’s strange, we’ll look into it”.
Not content to leave it there, I reach out to Digikey directly. I get connected to one of their technical sales representatives via an on-line chat, and after a bit of conversing, I confirmed that in fact the parts are shipped to Digikey as blanks, and they have a machine that can program the parts on-site. The technical sales rep also confirms the machine can program that exact configuration of the part, but because the part is not listed on the website I have to do a “custom part” quotation.
Aha! Now we are getting somewhere. I reach out to their custom-orders department and request a quotation. A lady responds to me fairly quickly and says she’ll get back to me. About a week passes, no response. I ping the department again, no response.
“Uh-oh.”
I finally do the “unthinkable” in the web age – I pick up the phone, and dial in hoping to reach a real human being to plead my case. I dial the extension for the custom department sales rep. It drops straight to voice mail. I call back again, this time punching the number to draw a lottery ticket for a new sales rep.
Luckily, I hit the jackpot! I got connected with a wonderful lady by the name of Mel who heard out my problem, and immediately took ownership for solving the problem. I could hear her typing queries into her terminal, and hemming and hawing over how strange it is for there to be no order code, but she can still pull up pricing. While I couldn’t look over her shoulder, I could piece together that the issue was a mis-configuration in their internal database. After about 5 minutes of tapping and poking, she informs me that she’ll send a message to their web department and correct the issue. Three days later, my part (along with 3 other missing SKUs) is orderable on Digikey, and a week later I have the 300 missing oscillators delivered directly to the factory – just in time for the start of SMT production.
I wrote Mel a hand-written thank-you card and mailed it to Digikey. I hope she received it, because people like here are a rare breed: she has the experience to quickly figure out how the system breaks, the judgment to send the right instructions to the right groups on how to fix it, and the authority to actually make it happen. And she’s actually still working a customer-facing job, not promoted into a corner office management position where she would never be exposed to a real-world problem like mine.
So, while Mel saved my production run, the comedy of errors still plays on at Element14 and Newark. The “unfindable order” is still lodged in my Element14 account, probably to stay there until the end of time. Newark’s “international” department sent me a note saying there’s been an export compliance issue with the part (since when did jellybean oscillators become subject to ITAR restrictions?!), so I responded to their department to give them more details – but got no response back. I’ve since tried to cancel the order, got no response, and now it just shows a status of “red exclamation mark” on hold and a ship date of Jan 2022. The other Singapore Element14 order that was combined with the Raspberry Pi still shows the ominous “please contact us for delivery” on the ship date, and despite trying to contact them, nobody has responded to inquiries. But hey, Digikey’s Mel has got my back, and production is up and (mostly) running on schedule.
This is just is one of many supply chain war stories I’ve had with this production run, but it is perhaps the one with the most unexpected outcome. I feared that perhaps the issue was intense competition for the parts making them unavailable, but the ground truth turned out to be much more mundane: a misconfigured website. Fortunately, this small corner of the supply chain is now fixed, and now anyone can buy the part that caused me so many sleepless nights.








































{kind=link}