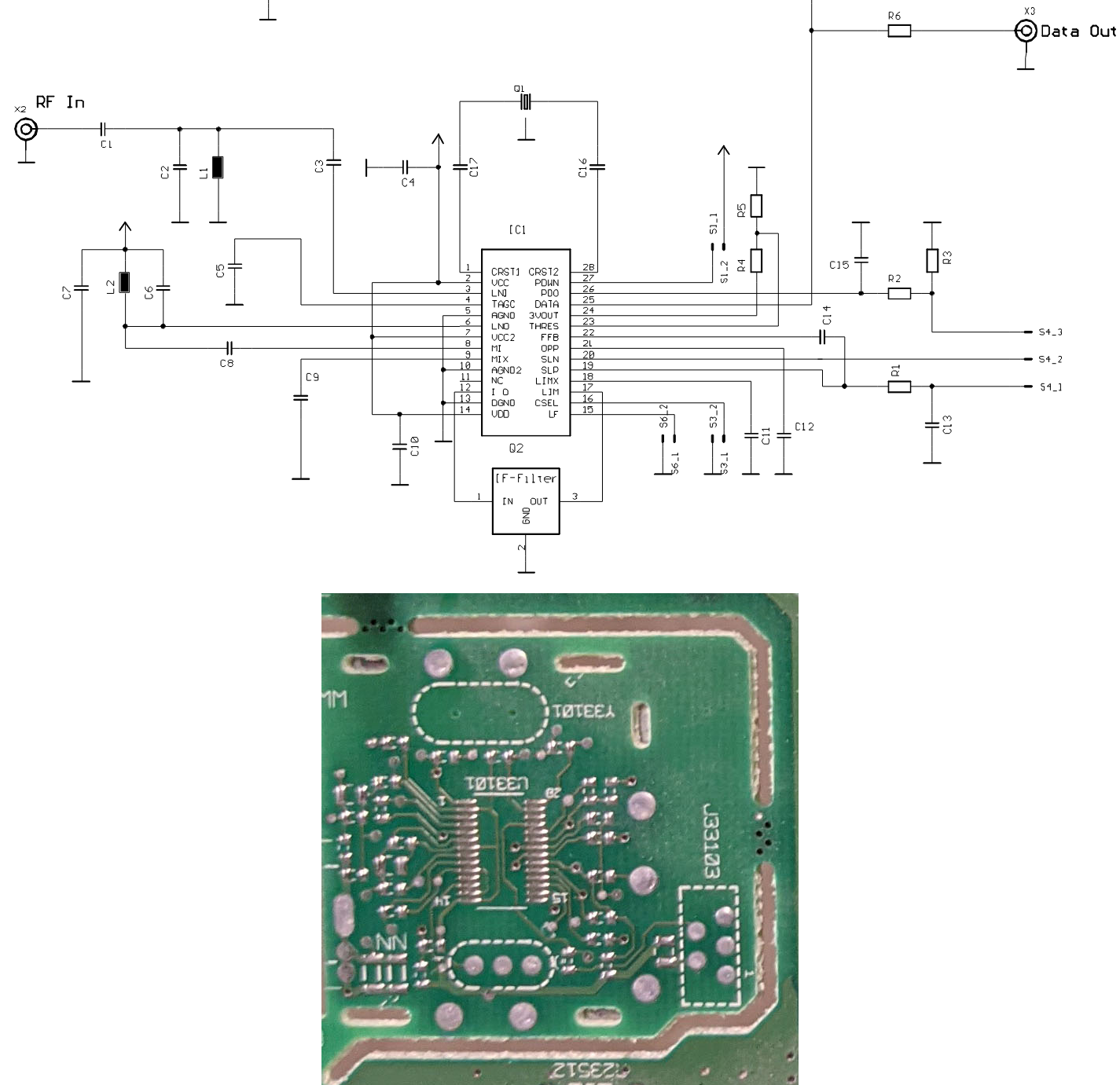
Wow! The ware for September 2021 was a real stumper. To be honest, when Marcan showed me the wares, I had similar instincts to most of those who entered guesses — I was entirely thrown off by the spendy choice of components combined with the huge array of multimedia connectors. Before seeing this ware, I never associated “karaoke” with “expensive electronics”; well, maybe this is a datapoint on how lucrative a business karaoke must be.
TL;DR: The Ware is a Joysound F1, and the winner is Thorkell, who finally managed to piece together the puzzle the day before the contest was scheduled to end. Calvin was actually the first to guess the correct genre of the machine, but Thorkell came as close as possible given the provided images to correctly identifying the make and model (not enough info was in the photos to reveal if it was the f1 or the fR model). Congrats, email me for your well-earned prize!
Marcan, who you should definitely follow if you have any interest in Linux, reverse engineering, and/or the M1 from Apple (he will be live-streaming an Asahi Linux bring-up on Nov 1!), also kindly provided this very detailed write-up on the ware:
Marcan’s Insights on the Joysound f1
This is a Joysound f1 (codename “Ken”), one of the more popular karaoke machines used in shops across Japan. It was released in 2012. You’re likely to have used one if you’ve been around more than once or twice. There are, to my knowledge, no previous teardowns of these machines on the internet, so I was intrigued by how they worked. I picked one up in an auction, and I will say I was not expecting what I saw when I tore it apart!
These machines are “networked karaoke” and periodically call home to update the song database (and require an ongoing subscription to work), but they are designed to work on anything from FTTH to periodic dial-up connections, so they need to have all the data locally. To that end, there’s a big 3TB hard disk with (almost) the entire song database (it is subsetted differently depending on your network speed, e.g. you won’t get many background videos on dial-up, and songs published as user submissions are always streamed on-demand and available only on broadband configurations). The HDD also contains firmware, updates, and anything else that needs pushing out to machines. As of the August update they seem to be using 2.5TB of the storage capacity, so it’s pretty tight already!
The architecture is bizarre. The Tegra 2 SoM is the main processor of the system, running Linux4Tegra (Ubuntu 10.10 ARM32) with good old Xorg; it is in charge of the main karaoke playback, networking, updates, remote control service, etc. Interestingly, it can also peer with another machine to serve its data over the network, which is useful when an HDD dies, to avoid having to take the machine out of service entirely. It boots off of a ramdisk loaded off of the HDD, and quite impressively, the entire rootfs is less than 150MB uncompressed. Control is usually via external touchscreen or tablet remotes, that connect typically via an external Wi-Fi access point and network, but can also use the internal Wi-Fi card in ad-hoc mode.
The entire audio subsystem is offloaded to the Roland board, which has a full MIDI synthesizer (for the karaoke; most songs are MIDI, although AAC is also supported and decoded by the Tegra before being pushed to the Roland as PCM) and DSP engine for Mic effects (reverb, voice changer, anti-howling, etc). In fact, it even has a fancy system for using an external microphone to measure the acoustic characteristics of the room and automatically compute a DSP profile. On top of the core MIDI patches, the Tegra also uploads an extra set of very high quality bass and drum samples to the Roland via the USB connection. Talk about high-end MIDI!
All the I/O is for things like the mics, external background music/video sources, instrument inputs (e.g. you can add a guitar preamp frontend), and auxiliary outputs. This is the first machine in its range to have HDMI, so it only has a single output; a newer revision called F1v added an HDMI input and dual HDMI outputs, to allow for HDMI idle/background video feeds.
The front touch panel is driven by the Marvell Armada SoC and is its own system running Android Eclair. It gets an SD feed of the main system’s video to display when idle, and it can composite its menus on top. It is otherwise a completely standalone system, with its own song metadata database updated from the main unit, etc. It communicates with the main system chiefly via USB networking and some of the same APIs that external Wi-Fi remotes would use. This is the first machine from Joysound to have an embedded touchscreen interface, and basically what they did was take the existing JR-300 “Mary” stand-alone touchscreen remote and embed it into the main unit. They call it “pamary” (Panel Mary, presumably). Amusingly, the ad-hoc Wi-Fi dongle is connected to the Armada, not the main SoC, so external remotes connected in this way end up routing through it into the main SoC. No idea why they did it like that.
The next generation (Joysound MAX “Zeus”) is basically an iteration of the same architecture. They ditched the Tegra 2 and replaced it with a Renesas R-Car-H2 (keeping with the automotive SoC theme…) and the distro is now Yocto-based, but the front panel SoC remains separate. The Roland board is much reduced, presumably using newer more integrated technology. The HDD is now 4TB. There is also a newer MAX2 version, which I don’t have, but I don’t expect it to be much different either.
Thanks for playing this Name That Ware! Hope you enjoyed it!